This is a quick-and-dirty implementation Fiddler on the Proof’s Reasonable Rankings for College Football. Their proposal uses the score-differentials between games. Once you have all the scores, you solve a linear equation to rank teams based on how the did against one-another, and even consider how they did amongst similar teams.
Data
Here I gather the data for the 2024 season from https://www.sports-reference.com.
Code
from types import SimpleNamespaceimport pandas as pdimport duckdbimport numpy as npimport requestsfrom bs4 import BeautifulSoupimport matplotlib.pyplot as pltimport seaborn as snsimport plotnine as pnurl ="https://www.sports-reference.com/cfb/years/2024-schedule.html#schedule"response = requests.get(url)soup = BeautifulSoup(response.content)# Find the table (inspect the webpage to find the correct table tag and attributes)table = soup.find("table", id="schedule")# use these table headersheaders = ["week","date","time","day","winner","winner_points","home","loser","loser_points","notes"]# Extract table rowsrows = []for tr in table.find("tbody").find_all("tr"): row = []for td in tr.find_all("td"): row.append(td.text) rows.append(row)# Create pandas DataFramescores_raw = ( pd.DataFrame(rows, columns=headers) .dropna(subset=["week"]))scores_raw.iloc[0]
week 1
date Aug 24, 2024
time 12:00 PM
day Sat
winner Georgia Tech
winner_points 24
home N
loser (10) Florida State
loser_points 21
notes
Name: 0, dtype: object
Here I clean up the scores table.
Code
scores = duckdb.query("""with scores as ( select row_number() over() as game_id , trim(regexp_replace(winner, '(\(\d+\))', '')) as winner , trim(regexp_replace(loser, '(\(\d+\))', '')) as loser , cast(coalesce(nullif(winner_points, ''), '0') as int) as winner_points , cast(coalesce(nullif(loser_points, ''), '0') as int) as loser_points from scores_raw where 1=1 and week is not null)select * , loser_points , winner_points - loser_points as diff_pointsfrom scoreswhere 1=1 and winner_points + loser_points > 0""")duckdb.query("select * from scores limit 4")
Construct the “game matrix,” which is made up of -1,0,1.
Each row represents a game
Each column represents a team
An entry is 1 if the team won that game, -1 if it lost that game, 0 otherwise
Each game will have a corresponding score, which we keep in another vector.
Code
teams = duckdb.query("""with teams as ( select distinct winner as team from scores union all select distinct loser as team from scores)select teamfrom teamsorder by team""")team_mapping = {team: i for i, team inenumerate(teams.to_df()['team']) }game_matrix = np.zeros((scores.shape[0], teams.shape[0]))for i, row in scores.to_df().iterrows(): game_matrix[i, team_mapping[row['winner']]] =1 game_matrix[i, team_mapping[row['loser']]] =-1"{} games, {} teams".format(*game_matrix.shape)
'919 games, 367 teams'
What’s a game worth?
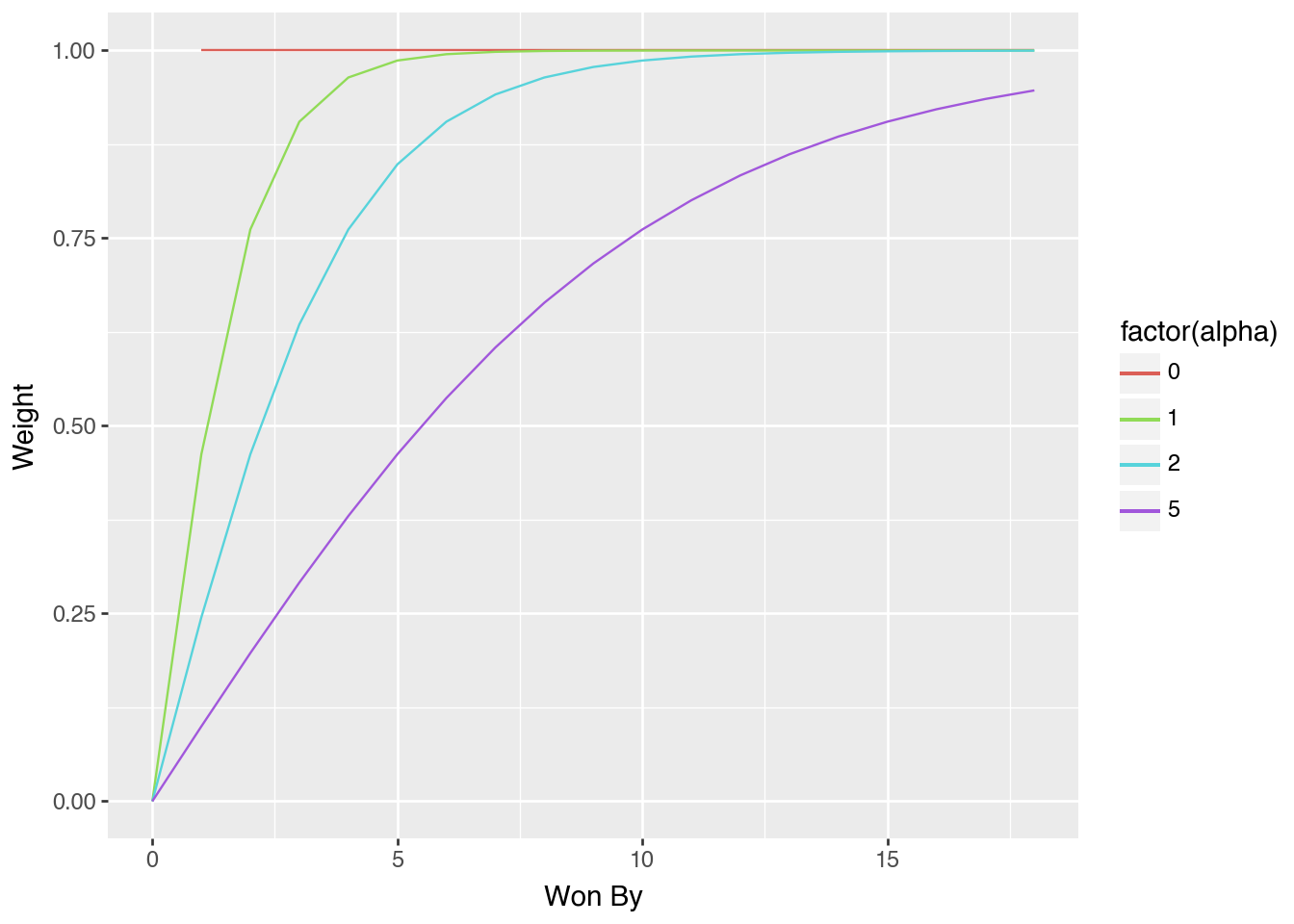
The Fiddler maps a score-differential to a weight between 0 and 1. They recommend the function below. It accepts the number of points the winners won by (i.e. a positive number) and returns a weight between 0 and 1 (1 is better than 0).
There has a tunable parameter, alpha, which means we can decide how to weigh different wins, e.g. - when alpha=0, “a win is a win,” so a team that wins by 1 point is just as good as a team that wins by 14 points - when alpha=5, a team that wins by 1 point doesn’t get a strong weight (closer to 0), while a team that wins by 14 points gets a weight of ~0.8.
As alpha increases, teams need larger point differentials to do well.
Code
( pd.concat([( pd.DataFrame({"Won By": np.arange(0, 19)}) .assign(alpha=a) .assign(Weight=lambda df: weigh(df["Won By"], alpha=a)) ) for a in [0, 1, 2, 5] ], ignore_index=True) .pipe(pn.ggplot)+ pn.geom_line(pn.aes(x="Won By", y="Weight", color="factor(alpha)")))